
这篇文章来自一次关于 Codex、Claude、OpenSpec 和个人开发流程的讨论。问题的起点很简单:为什么 Agent 明明完成了任务,结果却经常和高级工程师心里的“正确结果”不一致?
继续追问后,会发现真正困扰人的并不是“Agent 会不会写代码”,而是几个更深的问题:
- Spec 越写越多,人类读不动,也验不过来。
- Agent A 做事,Agent B review,Agent C 再判断 B 的 review 是否可靠,容易进入无限监督循环。
- 任务在沟通中不断分叉,细节决策越来越多,最后让人产生决策疲劳。
- 核心决策还没想清楚,Agent 却不断引出新的局部决策,导致人对它的编码行为失去信任。
- 一个简单协议设计,最后可能变成 spec、smoke test、review、架构讨论、验证脚本、回归测试的一整套重流程。
我把这个现象称为:Agent 协作中的认知负担转移。
过去我们花精力写代码;现在 Agent 能帮我们写代码,但它把一部分负担转移到了“描述、审核、决策、验证”上。如果这些环节没有设计好,Agent 并不会让任务变轻,反而会让任务变得更像小型项目管理。
公开资料里,OpenAI 和 Anthropic 讨论了什么?
先说结论:公开资料里,很少会直接用“监工 Agent 是否可靠”“A 看 B 看 A 的无限循环”这种说法来讨论。但 OpenAI 和 Anthropic 都在反复强调几个相关原则。
OpenAI Codex 的公开最佳实践强调:把 Codex 当作可以长期配置和改进的队友,而不是一次性问答工具。一个好的任务应该说明四件事:
- 你要改什么或构建什么。
- 哪些文件、目录、文档、错误信息与任务相关。
- 需要遵守哪些架构、安全和工程约束。
- 什么条件成立时,任务才算完成。
OpenAI 还强调:复杂任务要先 plan,再编码;重复出现的约束应该沉淀到 AGENTS.md、配置、技能或自动化流程里;Codex 不应该只生成代码,还应该运行测试、检查、review diff。
Anthropic 在《Building Effective Agents》里强调:成功的 Agent 系统通常不是复杂框架,而是简单、可组合的模式。能用普通工作流解决的,不要一上来就做完全自治 Agent。对于明确任务,用预定义 workflow 更可控;只有开放式、难以预先确定步骤的任务,才适合更高自治度的 Agent。
Anthropic 在关于工具的文章里也强调:Agent 可靠性的关键不是“多套一层 Agent”,而是为 Agent 提供清晰、可测、上下文友好的工具与评估。工具说明、返回信息、评估集、验证器都会显著影响 Agent 的表现。
这些实践合起来,可以转化为一个适合个人开发者的原则:
不要追求“Agent 自己证明自己完全正确”,而要把任务切成少量关键决策、明确边界和可验证证据。人只判断高价值决策,机器和 Agent 负责低价值验证。
为什么 Markdown Spec 会变成负担?
Markdown 本身不是问题,问题是 Agent 很容易把 Markdown 写成“长篇思考日志”。它看起来完整,实际上不利于审核。
常见症状:
- 背景、目标、方案、风险、任务、测试混在一起。
- 同一个决策在多个段落重复出现。
- 临时想法和已确认决策没有区分。
- Spec 一边执行一边膨胀,旧内容没人清理。
- 人类每次 review 都要从头读一遍。
我没有在公开资料里确认“Claude 内部越来越多使用 HTML 做文档”这条具体说法;但从工程实践上看,很多团队转向更结构化、视觉化的文档形式并不奇怪。HTML 的优势不是“格式更华丽”,而是可以把信息分层:摘要、状态、决策、风险、待办、证据可以分块呈现。人类不必读完所有细节,也能先抓住重点。
但对个人开发者来说,不一定非要切换到 HTML。更重要的是:文档结构必须服务于决策,而不是服务于记录所有过程。
我更推荐使用短文档结构:
spec/
overview.md # 目标与范围
api.md # 接口和协议
decisions.md # 决策记录
src/
tests/
docs/
notes/其中每个文件职责清晰:
overview.md:只写目标、非目标、验收门禁。api.md:只写协议、接口、数据结构。decisions.md:只写核心决策、延后决策、替代方案。notes/:放临时想法,定期整理,不作为执行依据。
这样比一个不断膨胀的 spec.md 更可维护。
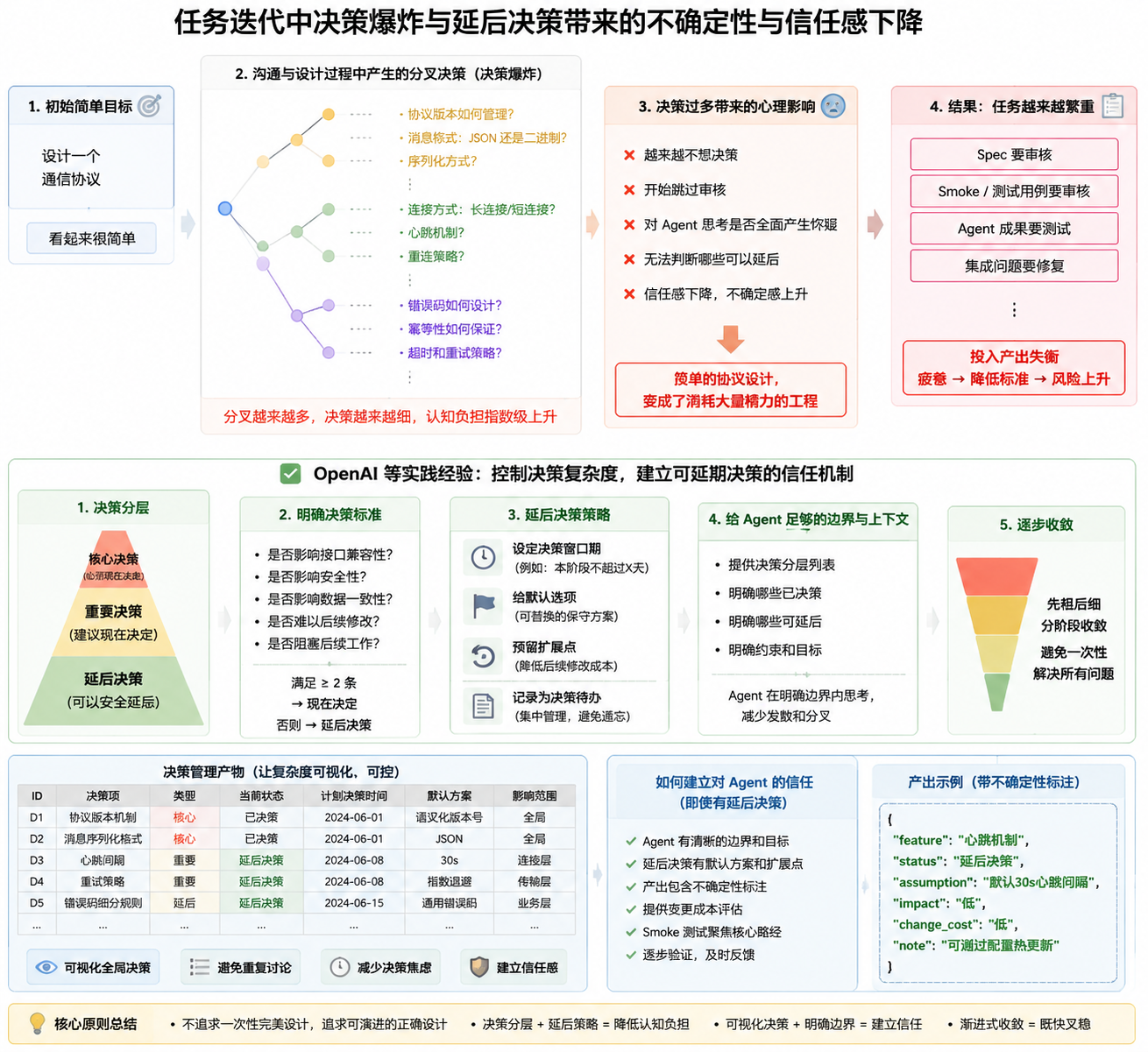
核心问题:决策爆炸与信任感下降
在和 Agent 设计任务时,很容易出现一个现象:本来只是想设计一个通信协议,聊着聊着就变成了几十个分叉决策。
比如:
- 协议版本如何管理?
- 消息格式用 JSON 还是二进制?
- 序列化方式是什么?
- 连接方式是长连接还是短连接?
- 心跳机制怎么做?
- 重连策略怎么做?
- 错误码如何设计?
- 兼容性如何保证?
- 超时和重试策略是什么?
每一个问题都看似合理,但它们叠在一起,会让一个简单任务迅速变重。
更糟的是,当 Agent 不断提出新决策时,人会产生一种不可靠感:如果现在又冒出这么多决策,那是不是说明它前面想得不够全面?如果核心决策还没稳定,我怎么敢让它继续写代码?
这就是任务迭代中的“决策爆炸”。
解决它的关键不是让 Agent 一次性想完所有问题,而是建立一个“决策分层”机制。
决策分层:哪些必须现在定,哪些可以延期?
我会把决策分成三层。
1. 核心决策
核心决策一旦错了,后续实现大概率要推倒重来。
例如:
- 协议是请求响应式,还是事件流式?
- 数据模型的主键和生命周期是什么?
- UE 插件功能是 Editor-only,还是 runtime 也要支持?
- Python 插件是命令行工具、GUI 工具,还是库?
核心决策必须先定,不能轻易延期。
2. 重要决策
重要决策会影响实现质量,但通常可以通过适配层或局部重构调整。
例如:
- 默认超时时间。
- 错误码分类。
- 日志格式。
- 配置文件位置。
- 是否先支持批处理。
这些建议现在定一个默认值,但允许后续替换。
3. 延后决策
延后决策不影响当前最小可行目标,可以安全推迟。
例如:
- 是否做复杂可视化面板。
- 是否支持多种协议编码。
- 是否做完整性能分析 UI。
- 是否支持插件市场式扩展。
延后决策不是忽略,而是记录到 decisions.md,并设置决策日期或触发条件。
一个简单规则是:
如果这个决策不影响接口兼容性、安全性、数据一致性和后续可测试性,就优先延期。
这样可以避免每次设计都变成全面架构评审。
监工 Agent 是否可靠?
监工 Agent 的输出当然不应该无条件相信。它本身也会漏看、误判、过度挑刺,甚至为了显得专业而制造复杂度。
所以监工 Agent 不应该承担“最终真理”的角色,而应该承担“结构化检查器”的角色。
它的可靠性来自三个方面:
- 输入是否清晰:它审查的是明确 gate,还是模糊的“帮我看看”?
- 输出是否可验证:它指出的问题能否对应到文件、代码行、测试或行为?
- 是否受限于职责:它是审 spec,还是审质量,还是审安全?不要混在一起。
我更倾向于把 review 拆成两种:
Spec Review
只问:有没有满足约定?有没有多做?有没有漏做?
输出格式:
Verdict: PASS / FAIL
Missing requirements:
Scope creep:
Evidence:
Required fixes:Engineering Review
只问:实现是否符合工程质量?
输出格式:
Critical issues:
Important issues:
Minor issues:
Verdict: APPROVED / REQUEST_CHANGES如果 review 的输出不能给出证据,不能指向具体文件,不能说明影响范围,就只把它当作建议,不作为阻塞项。
避免“A 看 B 看 A”的无限循环
无限 review 循环的根源,是没有定义“停止条件”。
一个实用的停止条件可以是:
- 自动检查通过:lint、type check、build、必要测试。
- Spec Review 没有 Critical/Missing requirement。
- Engineering Review 没有 Critical issue。
- 人类只确认 1 到 3 个关键问题。
不要要求 review 结果“完美”。只要求它把风险分级。
我会把问题分成:
- Blocker:必须修,否则不合并。
- Important:建议修,但可以由人决定是否延期。
- Minor:记录即可,不阻塞。
监工 Agent 如果不断提出 Minor,却没有 Blocker,就不应该继续拖住任务。
小结
Agent 协作变累,不是因为 Agent 没价值,而是因为我们把所有不确定性都摊在了人面前。
更好的方式不是增加更多 Agent 互相监督,而是减少需要监督的范围:
- 文档只记录可执行的决策,不保存全部思考过程。
- 决策分层,核心决策先定,细节决策可延期。
- Review 只看明确职责,不做无限泛化。
- 停止条件必须提前定义,不能让 review 变成新的任务生成器。
下一篇我会继续写:个人开发者如何把这些原则落地到 Codex、UE 引擎功能开发和 Python 插件开发中。
参考资料
- OpenAI Developers: Best practices – Codex
- OpenAI: Introducing SWE-bench Verified
- Anthropic: Building Effective AI Agents
- Anthropic Engineering: Writing effective tools for AI agents
- Claude Blog: Introduction to agentic coding